Cluster Sampling Analysis

Example
Consider a data set that contains fish density information (# fish per m-2) on YAO smelt collected in July 2007 on the southend of the main lake of Lake Champlain (this dataset can be downloaded at this link sml.csv). The data are in comma delimited format with column headers (the program skips the first line when reading in the file) with transect number in column 1 (integer format) and fish density in column 2. The area covered for this example is assumed to be 100 km2 or 100,000,000 m2 or in scientific notation 1.0e8 m2. Area is needed to expand the density estimates contained in the file to total abundance for the entire area of the survey. Typically the total survey area comes from a different source than the survey observations included in the file and thus is here entered in by hand into the table prior to using the file data to provide the summary calculations. The table below provides the expected results:
| Variable |
Value |
| n |
8 |
| mean m |
41.25 |
| mean rho |
0.088 |
| s2clu |
0.5744 |
| SE(rho) |
0.0065 |
| Area |
1.0e8 |
| N |
8.8e6 |
| SE(N) |
6.5e5 |
Theory
Cluster sampling may be used for systematic or random parallel transects or for zig-zag transects using only parallel zigs OR parallel zags.
Cluster sampling is an appropriate design and analysis method to consider for acoustics as clusters of observations are typically taken along a transect and not as, say, independent 1-minute sample units randomly scattered throughout the population. The clustered nature of the samples often requires that additional attention be paid to the type of analysis used so that the most can be made from the number of samples collected. A major advantage of this method is that it will weigh estimates according to transect length. Since transect lengths are seldom identical, this is the recommended method for acoustics surveys in general when geostatistics is not being used (see below).
In an acoustic example of cluster sampling:
Transects are clusters, and;
Horizontal bins are elements within clusters.
The first step is to compute an aggregate density estimate Pi across all the elements in each cluster i as follows:
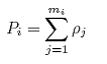 |
|
[42] |
where:
mi is the number of elements (bins) in cluster (transect) i;
ρj is density in horizontal bin j (#m-2);
Notice that Pi is also in units #m-2, but this is misleading as it Pi represents the sum of all densities and is therefore a function of the number of bins. If we multiply this estimate by the average area per bin we would get total number per transect, which is typically used in textbook presenting cluster analysis, but we leave that extra bit of calculation out here as, in the end, it cancels out.
We can compute the average density:
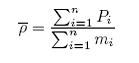 |
|
[43] |
where:
n is the number of clusters (transects) in the sample;
Pi is the agregate density observed in cluster i, and;
mi is the number of elements (bins) in cluster i, with i = 1,…, n.
The cluster variance (s2clu) and the standard error of the estimated average number per bin (SE(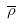 )) may then be found:
)) may then be found:
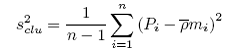 |
|
[44] |
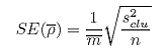 |
|
[45] |
where:
Pi is the agregate density in cluster i;
is the average number per bin over all clusters;
mi is the number of elements (bins) in cluster i, i = 1,…, n;
n is the number of clusters in the simple random sample; and
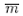 is the estimated average number of elements (bins) per cluster (transect), such that
is the estimated average number of elements (bins) per cluster (transect), such that
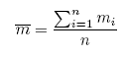 |
|
[46] |
Cluster sampling estimates may be expanded to total population abundance (N) by simply multiplying average density by area:
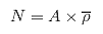 |
|
[47] |
where:
A is the total area;
is the average density (#m-2 area or #m-3 volume).
The standard error of the population abundance is:
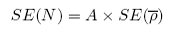 |
|
[48] |
where, again, SE() is the standard error of the estimate mean density derived from the cluster sampling method described above.
{kind=link}