Cluster Sample Size

Example
This program is set up to determine the standard error of the density given three choices for n (e.g. the number of transects: n1, n2, n3), a range of the number of bins per transect and the assumed cluster variance. See the section on cluster sampling for more details on this method.
The cluster variance (s2clu) and the standard error of the estimated average number per bin (SE(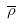 )) may be found as:
)) may be found as:
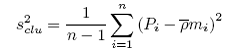 |
|
[44] |
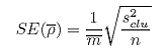 |
|
[45] |
where:
Pi is the agregate density in cluster i;
is the average number per bin over all clusters;
mi is the number of elements (bins) in cluster i, i = 1,…, n;
n is the number of clusters in the simple random sample of clusters (transects); and
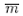 is the estimated average number of elements (bins) per cluster (transect), such that
is the estimated average number of elements (bins) per cluster (transect), such that
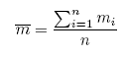 |
|
[46] |
The cluster variance, which is the variation in the agregate density, may be calculated from data collected in a previous or pilot survey. You may wish to use the value provided from the Cluster Sampling Analysis routine applied to your data. The value of 0.57, provided as a default in this example run, comes from a survey of smelt in Lake Champlain.
{kind=link}